
O que analytics engineers precisam saber de data science?
Analytics engineers podem potencializar sua carreira ao entender conceitos essenciais de data science. Descubra os conhecimentos que fazem diferença no dia a dia!
Se você atua com engenharia de analytics (AE), sabe que seu papel vai muito além de transformar e organizar dados.
A conexão entre engenharia de dados (DE), análise (DA) e ciência de dados (DS) é fundamental para que insights relevantes sejam gerados.
Mas até que ponto é necessário dominar conceitos de data science? E quais são os conhecimentos essenciais para tornar seu trabalho mais eficiente e alinhado às demandas do mercado?
Neste artigo, exploramos os principais conceitos de data science que podem ajudar analytics engineers a aprimorar suas habilidades, melhorar a comunicação com outros times e agregar ainda mais valor ao seu trabalho.
Vamos nessa?
Para início de conversa...
Analytics engineers têm ganhado bastante destaque nos times de dados modernos.
Isso se dá justamente por essa área poder atuar entre as diferentes pontas da cadeia de dados, servindo como ponte entre a engenheira de dados, a análise de dados e a ciência de dados.
Portanto, apesar de não ser necessário que profissionais da engenharia de analytics dominem todos os conceitos e ferramentas dessas outras áreas, é útil que conheçam alguns conceitos básicos para melhorar sua integração e comunicação com as demais áreas de dados.
Neste artigo, exploraremos alguns dos conceitos de DS que podem ser úteis para a AE.

Analytics engineering e data science: uma introdução
Analytics engineers podem potencializar sua carreira ao entender conceitos essenciais de data science. Descubra os conhecimentos que fazem diferença no dia a dia!
Uma das ocupações tradicionalmente atribuídas para profissionais de data science é o estudo de técnicas estatísticas, tratamento e análise de dados e sua modelagem usando técnicas de machine learning.
Neste sentido, há algumas semelhanças com o papel de analytics engineers, que utilizam fortemente o SQL como uma forma de agregar, tratar e estruturar dados que serão consumidos pela pessoa usuária final, unindo a infraestrutura de dados com a geração de valor.
Mas afinal, quais são as interseções entre as duas áreas?
As conexões entre analytics engineers e data scientists
O conhecimento básico de conceitos estatísticos e de técnicas de tratamento de dados comumente usadas na ciência de dados pode aprimorar o trabalho de engenheiras e engenheiros de analytics.
Como analytics engineers preparam dados para serem consumidos pela área de negócios, saber os diferentes tipos de análises que existem podem guiar seu trabalho.
Para isso, saber identificar os tipos de dados com que está lidando é essencial. Se a área de negócios precisa dos dados completamente tratados, saber lidar com dados ausentes e valores discrepantes podem ser necessários.
Além disso, na era do big data, em que milhões de dados são gerados e tratados continuamente, saber trabalhar com amostras de dados pode diminuir custo e tempo de trabalho.
E já que analytics engineering conta com ferramentas eficientes para processamento de dados, pode realizar também feature engineering nos dados para data scientists.
No fim, tudo isto pode servir para criar um dataset com dados coerentes, limpos, e corretamente organizado para a área de negócios. Explicaremos sobre cada tópico nas seções a seguir.
Análise descritiva, preditiva e prescritiva
Gosta de análise de dados? Espero que sim, pois temos várias opções no cardápio!
Existem diferentes tipos de análise voltada para diferentes objetivos. A seguir, vamos conhecer as principais.

Análise descritiva
A análise descritiva é o arroz com feijão da estatística, e tem como objetivo organizar e resumir os dados coletados, evidenciando suas principais características e padrões já existentes.
Essa abordagem utiliza diversas medidas estatísticas, como a média, mediana, desvio padrão, valores máximos e mínimos, além de recursos visuais como gráficos e tabelas para facilitar a compreensão.
Ela é extremamente útil para se ter uma rápida noção dos dados, e também para criar uma análise exploratória de dados (EDA), e podem ser diretamente utilizadas por analytics engineers para entender e/ou validar dados.
Análise preditiva
E quando precisamos ir além da simples descrição dos dados? Com a análise preditiva podemos modelar informações históricas para identificar novos padrões e tendências, mas principalmente para fazer predições.
Isso pode ser feito usando modelos matemáticos e algoritmos de machine learning, oferecendo uma visão antecipada de resultados futuros com base nos dados já observados.
Se a análise descritiva visa descrever os dados, a preditiva tenta representar os dados de forma generalizada e com um objetivo específico através do que chamamos de um modelo.
Análise prescritiva
A análise prescritiva é a união das análises descritiva e a preditiva com conhecimento de negócios.
Se a descritiva responde “o que nós sabemos?” e a preditiva “O que nós podemos saber?”, a prescritiva tenta responder “O que nós devemos fazer?”.
Integrando diferentes análises, simulações, modelagens e técnicas de otimização, a análise prescritiva fornece recomendações práticas e estratégias para tomada de decisão, considerando possíveis variações e impactos futuros.
Enquanto as análises preditivas preveem futuros possíveis, as análises prescritivas criam suas recomendações específicas para lidar com esses futuros.Identificação correta dos tipos de dados e sua aplicação
Responsável pela transformação de dados para diferentes áreas de negócio, na engenharia de analytics é fundamental conhecer os diferentes tipos de dados e como tratá-los. Os principais tipos são:
1. Dados quantitativos (numéricos):
Contínuos: podem assumir qualquer valor dentro de um intervalo, incluindo decimais.
Discretos: podem assumir apenas valores inteiros e contáveis.
2. Dados quantitativos (categóricos):
Nominais: categorias sem ordem ou hierarquia. Ex: cores (vermelho, azul, verde), estado civil (solteiro, casado, divorciado).
Ordinais: categorias com ordem ou hierarquia, mas sem uma diferença mensurável entre elas. Ex: nível educacional (fundamental, médio, superior), satisfação do cliente (ruim, médio, bom, excelente).
A correta identificação do tipo de dado e sua representação pode evitar resultados inesperados.
Por exemplo, uma variável nominal como “gênero” pode ser representada de forma textual como “masculino”, “feminino” e “prefiro não dizer” mas também de forma quantitativa discreta, como 1, 2 e 3. Nesse caso, apesar de possível, calcular a média desses números não faz sentido estatístico.
Além disso, é comum encontrar dados temporais representados como texto, fazendo com que o tratamento dessa variável seja necessário para garantir sua conformidade.
Limpeza de dados ausentes
Quando é necessário fazer a limpeza de dados ausentes durante a transformação, a engenharia de analytics pode ser uma peça importante na implementação de técnicas para tratar as lacunas de dados.

Para lidar com dados ausentes, pode ser feita uma imputação de dados, que consiste em substituir um dado ausente por algum outro valor.
Existem várias técnicas para fazer isso e a mais indicada depende do contexto, sendo as principais:
Imputação pela média: pode-se calcular uma média usando todos os dados para substituir os dados ausentes. Também é possível selecionar um conjunto de N dados mais próximos ao dado ausente e calcular uma média simples ou ponderada.
Imputação usando outras métricas: além da média, é possível usar a mediana, a moda ou valores definidos usando regras de negócio.
Forward-Filling: repete-se o último valor não nulo que antecede o dado ausente. Comum em séries temporais.
Backward-Filling: repete-se o primeiro valor não nulo que sucede o dado ausente. Comum em séries temporais.
Mas cuidado! A imputação de dados ausentes podem ter resultados adversos, como:
distorções nas distribuições e parâmetros estatísticos das variáveis;
e alterações nas relações entre variáveis, afetando a correlação e a interdependência entre elas.
Apesar da imputação de dados promover os problemas mencionados, a alternativa pode ser ainda pior: jogar dados fora.
Por isso, a imputação pode ser aconselhável nas seguintes circunstâncias:
os mecanismos que geram os dados ausentes são adequadamente entendidos;
temos informações auxiliares disponíveis com alta capacidade de previsão;
e os dados ausentes seguem um padrão aleatório ou depende de variáveis conhecidas.
Note que nem todo dado ausente é um vilão! Às vezes, um dado ausente pode ser proposital.
Por exemplo, é coerente que a data de pagamento de uma conta ainda em aberto seja nula devido ao pagamento ainda não ter sido efetuado.
Da mesma forma, nem todo dado presente é um mocinho!
É comum encontrarmos valores como 9999999 em dados industriais, quando um sensor não está devidamente aferido. Este dado apesar de não ser ausente, não apresenta valor.
Dica: sempre pergunte para a área de negócios o que um dado ausente pode representar.
Amostragem de dados
Em data science, o conceito de amostra está intimamente relacionado com sua definição estatística, em que uma amostra é um conjunto de dados coletados de uma população estatística por um procedimento definido.
Porém, se não for feito corretamente, podemos criar uma amostragem enviesada.

Apesar deste rigor estatístico não ser necessário para a engenharia de analytics, é sempre útil definir alguns pontos antes de fazer uma amostragem:
QUAIS dados serão amostrados, ou seja, QUEM é nossa amostra? Ex: todos os clientes de uma loja? Apenas clientes com que fizeram compra nos últimos 6 meses? Apenas clientes que não pagam em dia? Clientes de um determinado gênero/faixa etária/etnia?
COMO os dados serão amostrados, ou seja, que tipo de amostragem será feita?
Em data science, existem três principais tipos de amostragem:
Amostra aleatória simples: cada elemento da população tem a mesma probabilidade de ser selecionado de forma independente.
Amostra aleatória estratificada: a população é dividida em grupos homogêneos (estratos) e a amostragem ocorre dentro de cada estrato para garantir representatividade.
Amostra aleatória sistemática: os elementos são selecionados em intervalos fixos a partir de um ponto inicial aleatório, exigindo uma ordenação prévia da população.
Alguns data warehouses já contam com cláusulas que fazem a amostragem sem precisar ler todo o conjunto de dados. No BigQuery, temos:
Note que nem sempre utilizar dados amostrais é a melhor opção, e a decisão de usar ou não usar amostras precisa ser feita conscientemente.
Os seguintes prós e contras podem auxiliar nessa decisão:
Pontos positivos de usar amostras:
maior segurança e controle com relação aos custos com o processo de transformação de dados;
e menor tempo de processamento de dados, agilizando o desenvolvimento.
Pontos negativos de usar amostras:
maior tempo do projeto gasto com configurações no dbt para utilizar o processo de dados amostrais;
e, dependendo da amostragem, eventos raros podem não serem incluídos na amostra e só aparecerem na fase de testagem, aumentando o tempo gasto com retrabalhos.
Tratamento de valores discrepantes (outliers)
Outliers são valores muito diferentes da grande maioria dos dados ou que se destoam de um referencial.
O fato de que um dado é um outlier não significa necessariamente um erro, podendo representar eventos naturais, porém raros.
De qualquer forma, a presença de outliers pode afetar a análise, visualização e modelagem dos dados de formas drásticas,tanto para data scientists como para analytics engineers.

Se for necessário tratar outliers na etapa de transformação, pode ser útil saber as principais técnicas de data science voltadas para isso. Vejamos a seguir.
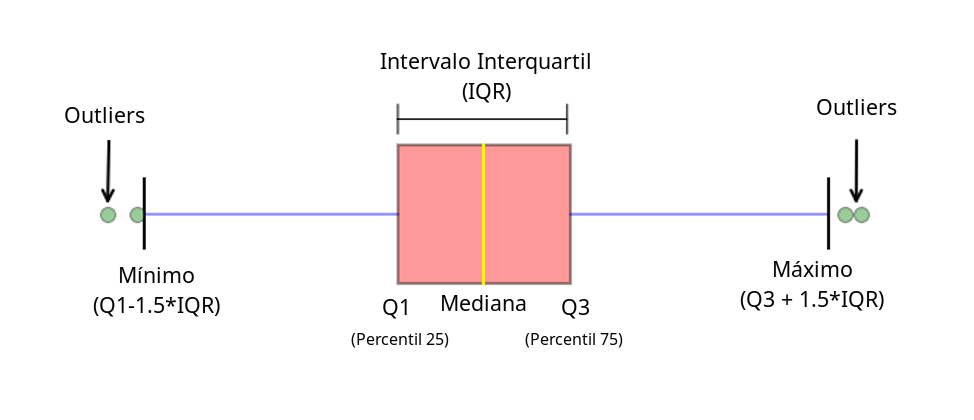
Método do Intervalo Interquartil (IQR)
Mede a dispersão dos dados entre o primeiro e o terceiro quartil (ou seja, 25% e 75% dos dados, respectivamente). Sua fórmula é dada por:
IQR = Q3 - Q1
Onde os outliers são definidos como:
Abaixo de Q1-1.5 × IQR
Acima de Q3+1.5 × IQR
O IQR é um método robusto e aplicável para diferentes tipos de distribuições de dados, além de ter uma interpretação visual simples e intuitiva usando o diagrama de caixa, ilustrado abaixo:
Método Z-score
Mede a distância de um ponto em relação à média em termos de desvios padrão. Pode ser calculado como:
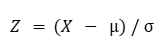
Feature Engineering
Consiste na criação de novas features, através da transformação de outras linhas e colunas, visando adicionar novas informações na etapa de data science. Confira alguns exemplos:
Combinação de variáveis: soma, diferença, razão ou outra operação analítica.
Codificação One-Hot Encoding: transforma categorias em variáveis binárias.
Codificação Label Encoding: converte dados categóricos em discretos.
Extração de componentes de datas: separação do dia, mês ou ano de uma data, ou identificação do dia da semana, se é dia útil, fim de semana ou feriado.
Criação de Lags (atrasos): no contexto de séries temporais, consiste em replicar o valor de uma coluna de uma N linhas atrás, onde N é o número do lag ou atraso.
Rolling Window (Janela Deslizante): cálculo de alguma métrica (média, mediana, etc) de valores dentro de um intervalo móvel ao longo do tempo.
Escalonamento: muda a escala dos dados para outro intervalo, usando diferentes técnicas estatísticas.
Binning: agrupamento de dados com valores contínuos em diferentes faixas.
Criação e organização de dados históricos
Data scientists rotineiramente realizam análises prescritivas e preditivas, que dependem de dados históricos devidamente organizados.
Usando os conceitos apresentados, analytics engineers tem pleno potencial para criar um dataset rico em informações, limpo e organizado.
E para manter e atualizar o dataset de forma eficiente, é possível usar features do dbtcomo modelos incrementais para processar somente novas linhas, e até atualizar métricas históricas usando somente dados novos, podendo reduzir substancialmente os custos envolvidos com processamento de dados.
Ao infinito e além: tendências
Existem diversos outros conceitos de data science que podem ser úteis.
Na medida que as noções de machine learning e inteligência artificial agregam cada vez mais valor, se torna fundamental que analytics engineers entendam melhor a área de data science, seja para melhorar seu desempenho no trabalho ou para se atualizar na área de dados.
Quer saber mais sobre analytics engineering?
A interseção entre analytics engineering e data science não é apenas um diferencial, mas uma necessidade para quem quer se destacar no mercado de dados.
Conhecer os princípios de estatística, análise preditiva e tratamento de dados permite que você não apenas otimize suas soluções, mas também trabalhe de forma mais integrada com cientistas e analistas de dados.
Quer aprofundar ainda mais seus conhecimentos e acelerar sua carreira na área? A Formação em Engenharia de Analytics da Indicium Academy é o caminho certo!
Inscreva-se por aqui e dê o próximo passo rumo à excelência em analytics engineering.