O
microbatch oferece o equilíbrio perfeito entre agilidade e eficiência no
processamento de dados, sendo uma solução poderosa no
dbt.
Com ele, você atualiza os dados em pequenos lotes, garantindo que as informações estejam sempre atualizadas sem sobrecarregar o sistema.
Ao processar apenas as mudanças desde a última execução, o microbatch é ideal para sistemas que exigem atualizações frequentes e desempenho otimizado.
Essa abordagem reduz a carga na infraestrutura e facilita o gerenciamento de grandes volumes de dados ou de alta frequência.
Descubra como aplicar o microbatch em modelos incrementais no dbt e otimize sua performance.
Microbatch é uma técnica de processamento de dados.
No contexto do dbt, o microbatch é especialmente útil para modelos incrementais, que são aqueles projetados para processar apenas novos dados ou dados alterados, em vez de recalcular toda a tabela a cada atualização.
Essa abordagem é bastante eficaz em cenários onde grandes volumes de dados são gerados com frequência e precisam ser integrados ao sistema de forma ágil e eficiente.
Agora, veja como o microbatch funciona em relação às demais abordagens de processamento de dados.
Vamos fazer um comparativo entre ele, o processamento em lotes (ou batch processing) e o processamento em tempo real.
Processamento em lotes: envolve coletar grandes volumes de dados e processá-los de uma só vez em intervalos regulares, por exemplo, diariamente ou semanalmente. É uma escolha eficaz para sistemas que não exigem atualizações instantâneas, mas pode resultar em atrasos até que os dados sejam disponibilizados, o que nem sempre é ideal para necessidades mais dinâmicas.
Processamento em tempo real: cada dado é processado assim que é gerado, oferecendo atualizações praticamente instantâneas. Embora seja ideal para fluxos de dados que exigem monitoramento contínuo e respostas rápidas, o processamento em tempo real demanda uma infraestrutura robusta e recursos de computação que podem tornar o sistema caro e complexo de manter.
Microbatch: combina o melhor dos dois mundos ao dividir os dados em pequenos lotes processados em intervalos curtos e regulares. Ele permite uma atualização mais frequente do que o processamento em lotes, sem a alta demanda por infraestrutura do processamento em tempo real.
Ou seja, o microbatch é o meio termo entre os dois tipos de processamentos anteriores: em lote e em tempo real.
E para ajudar você a saber qual das estratégias combina mais com as suas necessidades, separamos alguns fatores muito importantes para a hora de escolher a sua estratégia de processamento de dados.
Para optar pelo microbatch, é necessário ponderar, principalmente, dois fatores: o tempo de espera para ter seus dados processados e a eficiência computacional do processamento.
Latência de processamento: avalie quanto atraso ou latência é aceitável para o processamento dos dados. Isso pode variar dependendo da necessidade do projeto. Para alguns, atrasos de segundos podem ser aceitáveis; para outros, apenas alguns minutos ou até horas são toleráveis. Esse fator é crucial para definir o intervalo de tempo entre cada lote de dados.
Eficiência computacional: considere a eficiência do processamento, ou seja, o quanto de recursos computacionais, como custo, uso de rede e capacidade de processamento, vai ser necessário para lidar com o tamanho e a frequência dos batches definidos. Processar dados em microlotes frequentemente pode aumentar os custos e o uso de recursos, dependendo do volume de dados e da infraestrutura usada.
Por fim, dependendo do cenário, o uso de microbatch pode não ser vantajoso.
Em alguns casos, o custo e o uso intensivo de recursos podem não compensar os benefícios da redução de latência, sendo preferível adotar outra abordagem de processamento de dados.
O microbatch oferece o equilíbrio perfeito entre agilidade e eficiência no processamento de dados, sendo uma solução poderosa no dbt.
Usar microbatch em modelos incrementais do dbté uma maneira eficiente de lidar com cargas de dados grandes e dinâmicas sem sobrecarregar o sistema.
Ao dividir o processamento em pequenos lotes, o dbt pode integrar novos dados com mais frequência.
Dessa forma, é possível garantir que as informações estejam sempre atualizadas e prontas para análise.
Esse método também reduz o impacto nos recursos do banco de dados, pois evita que o sistema execute grandes operações de atualização e reconstrução da tabela completa, otimizando tanto o desempenho quanto os custos operacionais.
Com o microbatch, as empresas podem encontrar um equilíbrio ideal entre agilidade e eficiência no processamento de dados, mantendo uma infraestrutura sustentável e preparada para responder rapidamente às mudanças de dados.
Para entender um pouco mais da aplicabilidade do microbatch, vamos analisar um caso fictício.
Imagine que você vende picolés na praia e deseja registrar suas vendas em uma tabela. Ela ficaria conforme a imagem abaixo:
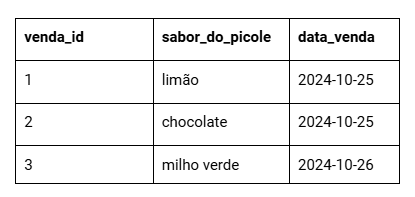
O trabalho parece simples, não é?
Contudo, à medida que o carrinho de picolés se transforma em uma sorveteria, depois em duas e talvez até numa franquia, a complexidade e o volume de dados aumentam.
Nesse último estágio, é comum a preferência por modelos incrementais devido ao custo de processamento.
Os modelos incrementais adicionam apenas registros novos, cabendo à pessoa desenvolvedora aplicar essa conceituação.
Isso pode ser feito, por exemplo, ao definir como novos registros aqueles cuja data_venda é igual ou superior à última carregada, com uma janela de tempo de três dias.
Assim, para cada data_venda realizada dentro do intervalo, os dados são substituídos por novos.
O código se estruturaria da seguinte forma:

O problema é que a execução de grandes volumes de dados em uma única consulta pode resultar em timeouts.
Imagine a quantidade diária de informações gerada pela sorveteria, com mais de 800 lojas no Brasil. Nesse cenário, o modelo incremental tradicional provavelmente não é suficiente.
Além disso, caso ocorra uma falha, a identificação do problema se torna complexa, exigindo o reprocessamento de todo o modelo.
A estratégia de microbatch resolve esses problemas ao agrupar os dados em períodos, e faz o processamento deles em consultas separadas.
Para isso, o modelo deve ser construído para ler e retornar um único lote de dados correspondente a uma unidade de tempo.
Essa abordagem traz benefícios significativos, tendo em vista que a independência dos batches melhora a gestão de erros, pois você pode utilizar dbt retry só no que falhou.
Além disso, ela elimina a necessidade de um bloco condicional de is_incremental().As configurações obrigatórias do microbatch são:
event_time: define a coluna de tempo que particiona os dados.
batch_size: define o tamanho do intervalo de tempo.
lookback: indica quantas unidades de batch_size devem ser consideradas para trás.
begin: indica o ponto de partida.
Em situações que exigem o reprocessamento de dados históricos, configurações adicionais como data de início (--event-time-start) e data de fim (--event-time-end) podem ser especificadas.
A equipe do dbt recomenda, ainda, configurar full_refresh: false para que os modelos de microbatch atualizem apenas as linhas alteradas ou adicionadas na fonte, evitando a recriação dos modelos.
Reescrevendo o exemplo acima, temos que:

Você também deve configurar um event_time para modelos upstream, como o stg_vendas_picole:

Com isso, a referência ao modelo é automaticamente filtrada.
Você pode desativar o filtro com o comando ref('upstream_model').render(), mas, sem ele, cada batch vai ter que escanear toda a tabela, o que pode aumentar o tempo de processamento.
Para saber mais, acesse a versão beta da estratégia de microbatch em modelos incrementais. Ela está disponível para o dbt Cloud Versionless e dbt Core V1.9. Para ativá-la, basta adicionar a seguinte variável de ambiente:

Aproveite!
Acompanhe nossas iniciativas gratuitas para ficar por dentro das técnicas, ferramentas e novas áreas de dados.
Além do nosso blog, temos o projeto Data Talks, que é uma programa de estudos com aulas ao vivo e gratuitas, a cada 15 dias, às segundas-feiras.
O tema dos encontros? Tudo que envolve dados, tecnologia e pessoas.
Vamos nessa?
Faça sua inscrição por aqui.
